Overview
The following section lists guidelines to consider when using (or planning to use) either of Bizagi features known as Data Virtualization or Data Replication.
Refer to the basic guidelines which apply as best practices to any project, and to advanced guidelines if customizing the Data Virtualization or Data Replication (when including bespoke code).
Basic guidelines
These basic guidelines will help you plan accordingly.
1. Proper analysis and design in early stages
It is strongly recommended to keep in mind any constraints, integration possibilities and proper design for modeling data (in analysis and design phases of your project implementation).
As Good practice, during your Data Modeling, you would need to consider which Entities and attributes would be integrated with an existing data source, and this includes:
•Defining the relationships between Virtual and Replicated entities, as well as other entities in your model.
•Using the 3rd normal form in your model (a.k.a. Normalization) to avoid duplication of information while keeping your relationships clear across your process.
2. Always map your attributes and Bizagi relationships (consider references to compound keys)
It is strictly required that you map Bizagi attributes to external columns of your external source bearing in mind:
•Which ones you will be using exactly.
•What type of information underlies in there (e.g, is it Unicode, its length, primary keys and constraints, etc).
•Using filters if applicable.
•Considering the relationship attributes which are created in Bizagi.
Note that these attributes belonging to Bizagi will also need to be mapped.
For more information and guide about this configuration, refer to the How to configure Virtualization example, in which you may also see how to do this when a reference to a compound key is included.
3. Explicit ports (applies when integrating to an SQL Server data source)
When using SQL Server as an external data source, it is strongly recommended that the database's instance configuration has an explicit TCP port:
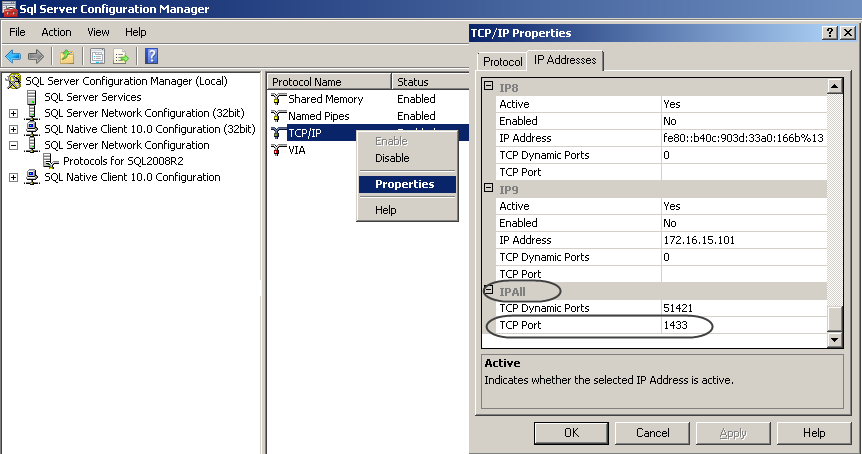
Using an explicit TCP port follows best practices (instead of the TCP Dynamic Ports alternative). It is recommended to use port 1433 for this configuration, as data is encrypted through this port.
4. Virtualization working in Production
Take into account that once a virtual entity is operational in a Production environment, you may not convert it into a non-virtual entity.
Once an external data source (registered as a system in Bizagi) has been deployed to a Production Environment, it will be not possible to edit its settings so that it is not used by virtual entities.
This means ensuring which tables should and which ones should not be virtual, and this must be defined previously to deploying the Processes and using them into production.
In case you do need to stop using Data Virtualization for your project, you will need to create a new process version and make sure that your process data model considers an alternate entity (which is not set as virtual).
In a similar way, you may not convert a non-virtual entity into a virtual entity once it is set up in a Production environment, and so you will need a new entity.
Proper cautions need to be considered for existing values and business keys.
5. Entities names
If you are integrating data sources having really long names (in its tables or columns), acknowledge that in Bizagi you will end up having a data structure mapped to your source, supporting the long name at the source, but having in Bizagi a name truncated.
This is so because with Data Virtualization or Data Replication Bizagi will add up a suffix.
Recall too that this applies for object's names (mainly for internal use) and not for display names (which should be the ones end users refer to).
|
If your data source (its table name or columns' names) has blank spaces, then you will need to make sure you configure and map the source by escaping the name with the appropriate characters to handle blank spaces in that database engine (e.g using [] in SQL Server). |
6. Appropriate primary keys and unique indexes
Recall that in order to use Data Virtualization or Data Replication, it is required that you external source has to comply with the following:
•Have a primary key definition whenever it is a table. If it is a view, then you need a unique index.
•When defining the primary keys in your external tables, recall that it is not recommended to rely on string data types for this purpose (e.g varchar, text, etc).
Primary keys indexing and performance is affected when using such data types and should be avoided.
7. Using Views when applicable
Bizagi Data Virtualization and Data Replication supports views.
You may use views when applicable, as long as these views can guarantee uniqueness in their records (i.e, there is a column, or set of columns, which make sure this and which can be taken as a business key).
|
Usually, views are meant for read-only purposes.
However, keep in mind that when using a view in which you want to update information from Bizagi (and when this view is built from more than 1 source table), the database engine by itself may have some restrictions. For instance, in SQL Server, such type of views will only allow you to update information in the base table (for more information, refer to https://msdn.microsoft.com/en-us/library/ms187956.aspx). |
8. Virtual Entities having virtual and non-virtual attributes when needed
It is important to acknowledge that if you have both virtual and non-virtual (local) attributes in a Virtual entity, you need to pay special attention on how you design your forms and business rules in general.
Take into account that a mixed model should be only used when needed, because having both types of attributes would imply that you should control from its very design, so that you don't run into performance issues.
Performance issues may arise given that filters of information should consider if the attributes to filter by, are virtual or are non-virtual.It is not recommended to allow or build filters which combine both types of attributes in these situations.
In case you consider that the Process' data model requirements would need additional attributes for a virtual Entity and if you wish to avoid potential performance issues, then these can be created in a separate Entity (which has an Entity reference attribute to the virtual Entity).
In the following data model example of a Bizagi Process, the additional attributes "Observations" and "Total Accounts" for a customer are created in another entity ("Customer_AdditionalInfo") which references the virtual Customer entity:
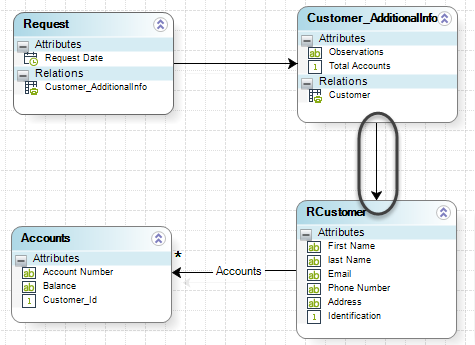
|
The importance of this guideline is focused on how Data Virtualization performs searches and synchronization for records in virtual Entities (which is done directly at the data source). Hence in a mixed model, queries and filters ran at the source could not be optimal. |
9. Include within the Data Virtualization or Replication, those entities which are referenced by virtual entities
It is important that you design your data model bearing in mind that you should always include within the Data Virtualization or Replication, any entities which are referenced by attributes in entities which are virtual or replicated (strongly recommended).
This applies as well recursively, for those entities added if in turn they reference other entities.
10. Replicate first if virtual Entities relate to replicated Entities
When having a mixed model where you use both Data Virtualization and Data Replication, and you have a virtual Entity which has a reference attribute to a replicated Entity, make sure that replicated records (those at the Parameter Entity) have been previously synchronized.
For this, you may set periodical executions of Replication accordingly.
11. Alternatives to Virtualization in PaaS
1.The preferred approach is to build a REST API which runs on the-prem environment and encapsulates access to the external system.
After, a custom connector which consumes the API must be generated or built. This connector will be used from the Bizagi processes to act on the external system.
a. Not all the data is used at once, but rather a specific query is made and data is later updated based on that query. Both cases can be supplied with an API.
b. In addition, it's safer to identify a few business actions that operate in the external system, rather than giving full access to replicated or virtualized data. This is another advantage of the API.
c. Finally, APIs are easier to maintain and monitor, and adapt fully to the runtime characteristics of a cloud environment.
2. If the above approach is not possible, a custom connector can be made. It should isolate access to the external system and handle latency problems, retries, and others that may arise when accessing the external system.
a. In the case of an external system, it depends on the existence of Node.js libraries.
b. In any case, the performance of the connector and Bizagi depend entirely on the connectivity of the external system, and the possible latency that may occur. This is not the case for option 1.
3. If the above is not possible, it would be necessary to create a Component library that isolates access to the external system. However this is not the preferred approach as it might bring compatibility problems: the library may have incompatible dependencies with web apps, updating the library require logistically complex procedures, and maintenance and problem-solving can become complex as well.
Last Updated 1/6/2022 11:16:07 AM